Pseudo-random numbers appear random
Programming languages all provide some means of generating random numbers. Those numbers aren’t truly random, though. They’re what’s called pseudo-random. They’re actually generated by a known, deterministic process for generating a sequence of numbers, but that process generates a long series of apparently random numbers that doesn’t repeat for a very long time. Since we don’t know the process behind the generation of those numbers, and they’re evenly and quasi-randomly distributed, we accept it as a random sequence of numbers.
We accept as “random” any series of numbers that seems to have no explicable pattern or reason. The fact is, though, that the reason or pattern might in fact be completely non-random, but if we don’t know or understand the process by which the numbers were generated, we might find the sequence to be incomprehensible and thus just “noise” or randomness. It’s important to realize that something might be quite sensible to those who are privy to the “grammar”, the means by which information is encoded, and yet might be completely incomprehensible to those who don’t know the encoding.
In short, randomness may well be in the eye of the beholder, and the difference between sense and nonsense may also be at least partially dependent on the knowledge of the beholder.
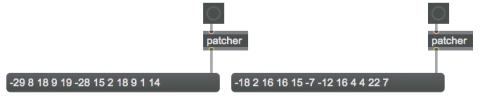
This patch is a simple demonstration of that idea. It shows two lists of twelve numbers, each apparently random. They were generated by two different methods, contained in the patcher subpatches. Can you guess how the numbers were generated? In fact, one of the lists is not random at all. Can you guess which one? You’ll need to look inside the subpatches.