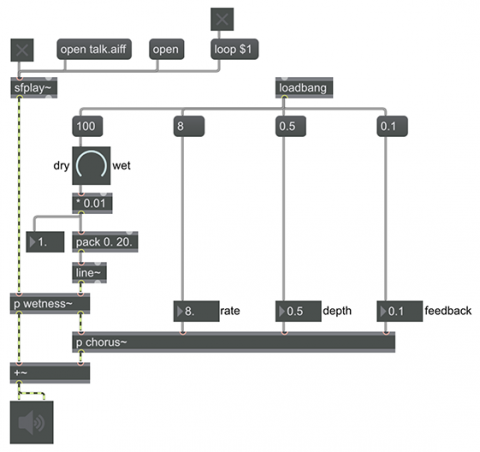
A basic chorus effect
The "chorus" effect is commonly used to enrich a sound. The effect gets its name from the way that a chorus of people singing or speaking in unison sounds different from a single person. By extension, a group of violins sounds different from a single violin (even though we don't call a violin section a "chorus"), and the same effect even takes place inside a piano because most of the hammers strike two or three strings tuned in unison rather than a single string. The effect occurs because of slight inconsistencies between the voices or instruments—the unision is not in fact a perfect unison—which result in unpredictable slight fluctuations in interference between the sound waves, causing the sound to be always just a little different. So, by applying that sort of effect to a single sound, we can create an illusion as if it were multiple versions of the sound being performed at once, like a chorus.
The way this is most commonly done is to make multiple copies of a single sound, each one slightly delayed and mistuned from the other so that they interfere with each other. Because human inconsistency is itself inconsistent—human performers are never imperfect in exactly the same way for very long—chorus effects most commonly include some slight randomization of the delays and mistunings. There are many variations on how to implement a chorus effect. This patch shows a common, computationally efficient, and relatively simple method, which takes place inside the p chorus subpatch.
At the core of the chorus effect are the tapin~ and tapout~ objects to create a feedback delay line, and the rand~ object to create a continuous slow random variation in the delay time. Unlike the noise~ object, which uses a new random number between -1 and 1 for every single sample in the signal, the rand~ object chooses a new random value between -1 and 1 at some rate other than the sample rate, and then interpolates linearly to that new value over the corresponding interval of time. So, for example, if the frequency value in the inlet of rand~ is 8 Hz, rand~ will choose a new random value once every 1/8 of a second and interpolate to arrive at that value over the course of the next 1/8 of a second. This creates a slowly and unpredictably fluctuating signal that is very different from the white noise of the noise~ object. (In effect, it is lowpass-filtered noise.) That fluctuating signal is used to control the delay time, which not only creates a continuously-changing interference effect when mixed with the original sound, it also creates subtle (or not-so subtle) fluctuations of pitch in the delayed sound.
The delay line's ring buffer created by the tapin~ object holds only 20 milliseconds worth of sound signal. That's enough for this effect, which we want to be subtle and fairly realistic rather than extreme and electronic-sounding. (Longer delay times are possible, of course, for more extreme effects.) The signal from rand~, which will vary between -1 and 1, is scaled and offset by the *~ 10 and +~ 10 objects so that the delay time can vary from 0 to 20 milliseconds. But first the signal from rand~ will be scaled by a "depth" factor in an additional *~ object. The depth factor is constrained between 0 and 1, so that when the depth is 0 there will be no effect from rand~ and the delay time will be a constant 10 ms, and when the depth is 1 the delay time can vary the full amount between 0 and 20 milliseconds.
The "feedback" factor is used to scale the amount of delayed signal that gets fed back into the delay line, mixed with the incoming signal, and re-delayed/detuned. When the feedback factor is 0 there will be no feedback, and we only get a single delayed/detuned version of the sound, but when feedback is greater than 0, the sound gets replicated over and over to create the effect of multiple voices. (The tapout~ object's delay time is internally constrained so that it can never actually be less than the duration of one MSP signal vector, allowing for its output legally to be fed back into the tapin~.)
Outside of the p chorus subpatch, we also have a p wetness~ subpatch, a simple cross-fader that allows you to control the mix of unaltered signal and chorused signal. Initially it's set to fully "wet", so that you hear 100% chorused signal, which allows you to hear what's going on in the chorus subpatch, but if you set the wetness somewhere between 0 and 100 you will get a mix between the altered and unaltered signals, which will cause them to interfere with each other.
Load a sound file into sfplay~, and experiment with the wetness, rate, depth, and feedback values to hear how each parameter affects the sound.