
When new technology is introduced to society, society generally takes some time to develop the use of it fully. This time lag is all the more pronounced with technology that is general in purpose, and is especially true of the computer, which is programmable to perform an almost unlimited variety of tasks. The development of computer hardware technology continues to progress exponentially, leaving the developers of computer software struggling to keep up with it. Although computers have been with us for decades, the variety of everyday situations in which they occupy a place continues to increase, and there are still many questions to be addressed regarding their use.
With almost any new technology, the first inclination is to use the new technology to duplicate already existent functions (test scoring, for example). This may be in order to demonstrate the usefulness of the technology, or it may be to eliminate the traditional--perhaps tedious, dangerous, or otherwise undesirable--method of performing the function. The second way of using technology is to perform previously unperformable but desired functions (telecommunication, for example). A third, less frequent, use of technology is to discover new, previously unconceived functions. For example, the idea of performing internal surgery without incision, by reflecting concentrated beams of light through fine, flexible cylinders inserted through an orifice in the body, would likely never have existed without the prior invention of lasers and fiberoptics.
So far, a large amount of the work done in computer music has involved the first way of using technology, trying to make computers behave in simulation of humans. In the making of music, however, the only activities which could really be termed tedious (and which we would therefore prefer to have a computer do for us) are technical instrumental practice (scales, arpeggi, etc.) and music copying. While it is unlikely that computers will help people become virtuosi without practicing (although the possibility may one day warrant consideration), many admirable attempts have been made to reduce the tedium--and to improve the speed and quality--of music copying. Attempts to duplicate other aspects of human musicmaking--composing, rehearsing, interpreting, improvising, listening--have proven somewhat less successful. Given that these are enjoyable human pursuits, one might reasonably ask, "Why try to duplicate these functions with a computer?"
There are different approaches taken to this question. One (not terribly inspired) approach might be termed that of the technician. Computers seem to entice a certain type of person having a basic fascination with technology itself. This fascination manifests itself in the attitude, "We have the technology. Let's use it." With neither a reasoned goal nor creative intuition as a guide, such an attitude--while perhaps admirable for its eagerness--usually results in aimless (and largely fruitless) experimentation. It can occasionally even be destructive when it results in malicious "hacking" or drives nuclear research in the defense department. Fortunately, computer music rarely if ever presents such destructive possibilities (with the possible exception of a rather odious type of sonic pollution).
Another approach is that of basic science, which holds that its goal is not to produce a specific usable product, but rather to contribute to the body of general scientific knowledge upon which applied sciences draw. There are many examples of the success of this approach in the scientific world--demonstrable benefits such as control of infectious disease and improvement of agricultural production. Computer science is still in its infancy, but we can already see the benefits of basic research in artificial intelligence, scientific imaging, etc. Concrete benefits in the even younger and more specialized--but highly ambiguous--field of computer music are more difficult to identify with general agreement. One concrete benefit which would almost certainly evoke no argument, because it does not depend on artistic taste, is the compact disc player.
A third approach, particularly applicable to research in artificial musical intelligence, is one I will call applied psychology. Proponents of this approach are primarily interested in the use of the computer as a tool for programming and exploring models of human cognition and intelligence. They maintain that our theories of human intelligence can be modeled by a computer program and then tested or that, working in the other direction, models of computer programming--or models from other domains, implemented as computer programs--can give us insight to our own cognitive and intellectual processes. The majority of this article will address this third approach: using computers to model human musical behavior.
Considerable work has also been done to enlarge the capabilities of musicians. Using complex calculations performable only by computers, one can give the illusion of recorded sound flying about through space--an idea dreamed of by the revolutionary thinker Edgard Varèse long before the development of modern computers. Composers have used computers to realize their conception of music unperformable by humans or as a tool to develop compositional ideas which would require amounts of calculation unthinkable without the use of a computer. A composer who imagines such novel music, and feels that it can be defined or better understood using an algorithm, can now write a computer program to test or realize the imagined music.
In the process of expanding our abilities with computers, we are likely to discover the third stage of technology: using it to do things we had not even considered previously. By defining and programming new functions--as opposed to merely imitating functions which humans already perform--one may enhance the composer's or instrumentalist's operations in ways previously unheard of, actually expanding the number of abilities at that person's disposal. This is exciting when you stop to think how much of what is considered musical is based on what humans can physically achieve. When such limitations are overcome, the realm of what is considered musical may be vastly enlarged.
Explorations in computer music can be (arbitrarily but usefully) divided into two large categories of concerns: input and output. What information goes into a computer and how is it handled? What information comes out of a computer and how is it generated? In practice, these two categories are closely interdependent, and roughly correspond to two categories of musical intellectual behavior: music cognition and music composition.
Attempts to model music cognition with artificial intelligence are usually approached as a way of increasing our knowledge of human psychology and intellect. Once an effective model of the music listener has been achieved, that model can be incorporated as part of a more complex model of an active musician, one which is listener, performer, composer, and improviser all at once. The more complex model can then presumably tell us more about the behavior of musicians, and perhaps even function in a musical society.
Computer cognition of music actually involves four unique problems. First, how will music be measured to provide input information to the computer system. Second, how will that information be presented to the computer? Third, how will it be represented in the computer program in such a way that the program can, in some way, come to some understanding of its meaning? And finally, what will the computer do with this knowledge?
The practical problem of measuring music is by no means a simple one. It involves making fundamental decisions at the outset as to what is important in musical sound. What will we attempt to measure? We have many culturally-established notions of what is important in music cognition, without really knowing why we believe them, or why different cultures have different ideas on the topic. For example, Western music notation and music theory tell us that what is important in music is that we must understand it as a set of separate simultaneous parametric dimensions (most of which are measured in fixed, discrete units): pitch, duration, loudness, instrument, etc. Pitch is measured logarithmically in twelve equal units per octave, duration is measured in integer divisions of a constant time interval, etc. Not only is the way of measuring these parameters highly dependent on culture, but the very idea of such a parametric breakdown of musical sound is very particular.
A Western college student must learn to "understand" a Beethoven symphony. The [Australian] aboriginal understands his music naturally. The Westerner can understand aboriginal music also, if he is willing to learn its language and laws and listen to it in terms of itself. It cannot be compared with a Beethoven symphony because it has nothing to do with it.[1]
Even remaining strictly in the context of Western classical music, phenomenological musical experience (not to mention scientific studies of sound perception) tells us that both the parametric breakdown and the units of measure are in many cases gross oversimplifications. When we listen to a flamenco or blues singer accompanied by a guitar, does the singer sing only the twelve pitches per octave played by the guitar? When we listen to a sustained tam-tam note, do we all agree precisely on the moment when that sound ends? When we listen to an orchestral texture, can we say with certainty exactly which instruments are playing? Is the information always important to us? Do different parameters remain distinct and of constant importance, or do they advance and recede in importance over time, with changes in the activity in each dimension?
Since, for purposes of computer input, we obviously cannot measure all aspects of a piece of music in any meaningful way, it does seem that we must decide on one or more parameters to measure. But we must bear in mind that the way we define and choose those parameters is based on culture, musical style, and even personal preference. A cognitive model will thus evince the biases of the programmer, and is almost necessarily restricted to the parametric model of music perception.
Once it has been decided what to measure, one must confront problems of how to measure. Let's assume that we are only interested in measuring two musical parameters--pitch and rhythm--and let's consider an example in which the music to be measured is a performance of the following excerpt.
Notation uses two notes to describe this music, and shows that the first note is C lasting 1 second and the second note is D-flat lasting 1/2 second. In performance, however, the sound changes in one continuous loudness "curve" over time, from silence (i.e., the ambient noise floor) to piano and back to silence. What we hear as the fundamental musical pitch (even disregarding for a moment problems of computer detection of the fundamental pitch, given the fact that many pitches are actually present in the timbre of a trumpet) also changes according to some type of continuous curve from C up to D-flat and down to some pitch below that starting C.
Here are just a few of the questions we need to answer before measuring anything. Do we hope that our measurement will accurately reflect the notation of pitch and rhythm? If not, what "interpretation" of the sound's pitch and rhythm do we hope it will accurately reflect? What will we use as the threshold of amplitude that constitutes sound as opposed to silence, i.e., what level above the noise floor will we consider the barrier of silence? Is that the only determiner of the beginning and ending of a note? Do we care to try to represent degrees of loudness during the course of the note? What resolution will we use to gradate loudness? What resolution will we use to gradate pitch? If we decide to gradate pitch at the resolution of twelve pitches per octave, where will the threshold be between C and D-flat--halfway between the two, or just at D-flat? How will that decision affect our idea of when the pitch changes?
Our answer to these questions will probably depend on whether we want our input to the computer to include the maximum possible amount of information or the minimum acceptable amount. This decision will, in turn, depend on how we plan to represent information in our program, and what we intend to do with the information. Supposing that we plan to represent the information as some type of two-dimensional array of pitches and corresponding durations, here are graphic representations of three possible measurements of our excerpt, in order from minimum information to maximum information. (N.B. These are not graphs of pitch over time; they are graphs of correlated input values over computer address.)
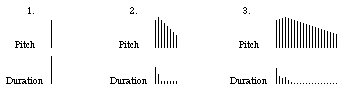
Clearly, as the amount of input information increases, so does the potential for detail of representation. If we were to translate these representations back into notation and perform them, their phenomenological similarity to the original sound would probably increase in direct proportion to the detail of the original measurement. However, in terms of accurately reflecting the notation that provoked the original sound (which we might assume in some way represents the composer's idea), none of these measurements has succeeded in extracting the proper information. The first measurement has detected a single note (which is not so dissimilar from the two notes slurred together in the notation) but ignores the pitch change entirely. The second and third measurements reflect the pitch change with some accuracy, but give a very different idea of the rhythm from that of the notation. We many note, though, that if we suppress those pitches which have durations below a certain threshold, the second measurement yields a reasonable reduction of the notation.
This gives us some idea of how our intended representation and use of the measurement influences what and how we measure. If our intent in this example were to reproduce the original sound, the maximum input information would be desirable. If our intent were to reproduce the original notation, the second measurement (possibly with suppression of very short notes) would be best. More mundane technical considerations of computer processing speed and memory size might also affect our decisions, but I'm assuming these are not problematic in this instance.
As a general principle, it is desirable that the input measurement have the maximum amount of detail allowed by our system of representation, on the assumption that the program will deduce the vital information algorithmically. In practice, however, primarily for reasons of ease of measurement and computer representation, one of the most common ways the designers of cognitive models measure music is to use a MIDI controller to capture data measuring performance gesture. Measuring performance gesture is hardly the same thing as measuring sound, but if the mapping between gesture capturer and sound generator is known and is sufficiently simple it can be accurately gauged and accounted for in the representation of the data. For example, if I know that key 60 of the controller plays a note of fundamental pitch middle C on the sound generator, and I know that the pitch bend wheel can cause a change of exactly �2 semitones in the pitch of the sound, then I know that the performance data "E0 00 50 90 3C 7F" is a measurement of the pitch a quarter tone above middle C at maximum volume. Use of MIDI does restrict one to measuring only those things which can be deduced from the relationship between the workings of the controller and those of the sound generator, but it provides readily available hardware for measurement, a well-known system of representation, and a wide variety of computer software environments for processing the data. These considerations explain MIDI's popularity for this type of research, despite its inherent limitations. (See also the discussion of MIDI in my article "Music and Language".)
Once the input data has been represented in the computer--say, as a time-tagged set of MIDI bytes--the computer program processes the data to interpret its significance. To examine ways of handling music data, let's consider a concrete problem of cognition, that of rhythm perception.
We perceive rhythm by detecting patterns of events in time. There are various theories of how we detect patterns in general, most of which can be seen as related in some way to basic grouping principles of Gestalt psychology--proximity, good continuation, closure, similarity, regularity, and common fate. More specifically musical aspects of pattern detection (which also can be related to Gestalt principles) include auditory streaming, hierarchical perception of structure and ornament, and notions of stylistic belongingness. We apparently employ many different means of detecting patterns, probably simultaneously as well as individually, both in conjunction with and in competition with each other.
Any method of pattern detection can be employed in processing musical data, to group together musical events which are determined to belong to the same pattern. In modeling our perception of rhythm, the time intervals outlined within the patterns of like events are used to hypothesize what might be the perceived (or intended) rhythm in a piece of music. This rhythm is then itself analyzed for patterns which may indicate organizational concepts such as pulse, beat, and meter.
The most obvious pattern for analysis is the simple detection of any event. If by event we mean the onset of a note, then we can hypothesize a rhythm based on an array of the intervals of time between note onsets. Although this is only one of a great many possible indicators of rhythm, it is the simplest and most obvious, and consequently is the most used. Unfortunately, many of the attempts at modeling rhythm perception have stuck with this one level of analysis, without considering the other delineators of rhythm which might support or conflict with the basic rhythm of note onsets. (Perhaps the daunting complexity of the problem, even with only a single delineator of rhythm, discourages researchers from adding new levels of complexity.) Before considering other factors in rhythm perception, let's look at the rhythm of note onsets.
The inter-onset intervals (IOIs) are first represented simply as an array of numbers showing the measurement in some absolute, musically objective units such as milliseconds. This array of numbers is the rhythm, but to derive some musical meaning from it one must detect patterns in the array. The method that seems most obvious for musicians (and virtually the only method that has been attempted by experimenters) is to attempt to compare this array of values to a likely notated target rhythm. Once the likely target rhythm has been determined, the numbers can be adjusted to conform to that rhythm and can then be expressed in relative rather than absolute terms. This is obviously useful if the end product we seek in our analysis is to output a notated score of the rhythm or to use the notation of the target rhythm as a basis for analysis. Most of the time most musicians do (to at least some degree) perform such a mental translation if the rhythm bears a close enough resemblance to an obvious notated solution. That is, one "forgives" slight "imperfections" with respect to some "ideal" target rhythm.
The extent to which a person employs this way of listening to and interpreting rhythm is quite dependent on a) the cultural background of the listener (i.e., the listener 's inclination to look for a certain target rhythm, based on his or her prevalent stylistic expectations), b) evidence of a particular musical style within the given piece or section of a piece which would suggest a certain type of target rhythm, and c) the relative simplicity or complexity of the music, which may encourage or discourage rhythmic analysis. To determine a target rhythm, a listener has to first determine a basic time interval--a beat or pulse--which must remain constant for some period of time. The IOIs will then be made to conform to some (usually small) integer multiple or division of the basic interval. This is the basis of many beat-tracking and rhythm-detecting algorithms,[2] of which we will examine a couple of representative examples.
In most computer implementations the unit of measure (such as milliseconds) is considerably smaller than the smallest interval to be considered a musical pulse. The input data must therefore be quantized--IOIs must be modified to conform to a reasonable musical pulse unit. What is the best method for performing this quantization? Most commercial MIDI sequencers use a simple rounding method of quantization, in which each event is rounded to the nearest multiple of a basic minimum quantum (e.g., the nearest 1/12 beat at some moderate musical tempo). This method makes no allowance for changes in the tempo of the performance. In order for an algorithm to make adjustments for changes in tempo, it must analyze the "errors" in the performance, i.e., the amounts by which the performed events had to be adjusted in the quantization process. This error can then be evaluated for significance and trends.
Discrepancies between performed rhythm and notated rhythm may be due to three factors. The first factor is the small deviations which inevitably occur due to motor error. The performer is simply physically unable to perform with the same machine-like precision that is being used to measure the performance. These slight errors are viewed as a sort of mathematical noise, and can be considered insignificant. Errors which are below a certain threshold can be ignored, averaged with the "ideal" notated value, or subtracted from the measurement of the adjacent value. The actual threshold can be either a specific amount of time or some percentage of the basic beat time.
A second factor can be called conceptual error. A performer's concept of when to play a note is always based on an estimate--albeit a highly educated one--of the proper point in time. Errors can and do occur in this estimation process. Both motor error and conceptual error are types of unintentional deviation from the notation. Without citing the source of their information, Desain and Honing state that the threshold of maximum unintentional deviation (which they term motor noise) generally ranges from 10 to 100 milliseconds. They do not comment as to the effect of beat speed on unintentional error.[3]
The third factor is intentional error, also known as rubato or expressive timing.
Expressive timing is continuously variable and reproducible....It is important to note that there is interaction between timing and the other expressive parameters (like articulation, dynamics, intonation and timbre).[4]
Deviations from nominal note durations may have the musical function of marking the meter [or] of marking musical structure. [Researchers have] managed to replicate rather accurately durational patterns in some piano performances by the principle of accelerating beginnings and decelerating terminations of structural units such as the phrase.[5]
Desain and Honing state that this expressive timing can result in deviations of "up to 50% of the notated metrical duration in the score."[6] The actual figure is extremely dependent on musical style. My own experience as a performer (including analysis of MIDI sequences of my own performances) is that deviation of timing is more restricted in Baroque music, for example, and that at the end of large structural units (such as the end of an entire piece) in Romantic music the deviation may exceed 50% of the notated time. The relationships of other aspects of the music (e.g., relationships of melody and accompaniment) will also affect rubato. The rubato of an unaccompanied singer, for example, is likely to be much more extreme than that of a singer who is being accompanied by a regular arpeggio pattern.
How does an algorithm evaluate quantization error and make decisions as to its intentionality and thus its significance? If the musical score is known in advance, the ratio of performance time to notated time can be plotted as a tempo map, indicating the continuous variation of tempo. However, in cases where the computer is detecting a previously unknown input, and hypothesizing as to its proper quantization and notation, a graph of the ratio of quantization error to an arbitrarily chosen quantum will yield a rather random distribution of values in the range �0.5. This indicates that for detecting the rhythm of (and hypothesizing a notation of) an unknown input, the program must continually revise its idea of the appropriate unit of quantization, which may or may not mean revising its idea of the beat tempo.
Almost all rhythm detectors work on the idea of expectation. Based on the rhythms perceived (or hypothesized) up to the present, the listener makes predictions of time points in the future on which new rhythmic events are likely to occur. The hypothesis is either confirmed or contradicted when the future rhythm either coincides with or differs from those predictions. When the hypothesis is contradicted, the program must then decide whether to interpret the deviation as unintentional (and modify it to fit the hypothesis) or intentional (and modify the hypothesis to fit it). The basic question is, "Does the deviation from expectation indicate a change in tempo?"
It is rather difficult to design a good control module that adjusts tempo fast enough to follow a performance, but not so fast that it reacts on every 'wrong' note. A common solution is to build in some conservatism in the tempo tracker by using only a fraction of the proposed adjustment. If this fraction, called the adjustment speed, is set to 0.5 the new tempo will be the mean of the old tempo and the proposed ideal.
A more sophisticated tempo tracker adapts its tempo only when there is enough confidence to do so. An onset that occurs almost precisely between two grid points will give no evidence for adjusting the tempo (because it is not sure in what direction it would have to be changed).[7]
Longuet-Higgins make use of a hierarchical structural description of rhythm and meter, looking for duple and triple divisions of larger note groupings. Chowning's method also uses a preference for simple ratios and incorporates knowledge of other musical aspects such as dynamic accents and pitch contour. A combination of these techniques might yield multiple interpretations of a given rhythm. Different interpretations could then be weighted according to some concept of their relative importance, or could have different powers of activation in a connectionist system.
Robert Rowe and the team of Desain and Honing have each approached this problem by designing connectionist systems which use expectation to make decisions about the quantization of a performance. In Desain and Honing's model, neighboring events are connected by "an interaction cell [to] steer [the events] toward integer multiples of one another, but only if they are already close to such a multiple."[8] The strength with which events are steered in this way is a function of how close they already are to being integer multiples of each other. As the process is repeated, the system's "confidence" in its evaluation of the rhythm increases.
Robert Rowe's improvisation program Cypher for Macintosh computer uses a connectionist listening network which maintains over one hundred theories of possible beat periods. Each theory has its own expectations regarding the onset time of the next event. Incoming events are evaluated with regard to how well they coincide with each theory's expectations. Lack of coincidence with a theory--i.e., syncopation--is considered a contradiction of that theory and is penalized. The incoming event is analyzed both with respect to its time interval from the last event and with respect to its time interval from the penultimate event. Thus two theories are immediately supported. A few other candidate theories are generated from a list of factors which are based on common integer subdivisions or multiples of the beat. The candidate theories are weighted in terms of how strongly they have been supported by "the evidence". Any nonzero theory which accurately predicted the event is given additional weight.
Rowe's beat tracker employs a clever scheme for attempting to accommodate rubato. If a candidate theory occurs in the vicinity of an existing nonzero theory, their weights are added and placed midway between the two theories. The candidate and the old theory are then zeroed, leaving only the new theory.
Neither of these connectionist methods makes clear how to deal with the issue of musical memory, which plays such a vital role in our own perceptions (particularly of characteristic rhythms). Too strong a memory in a connectionist system leads to the problems of hysteresis (delay) and blocking, whereby "prior states of [connectionist] networks tend to...delay or even block the effects of new inputs."[9] Activation of a unit must decay in the absence of continued resonance if such blocking is to be avoided in a music network. However, the fact is that our memory retention is very selective. We make decisions about what things are important to remember, and thus may remember things which happened very long ago--and about which we haven't thought in a very long time--better than we remember something relatively unimportant which happened only moments ago. Selective memory is very important in the perception of music; for example, we remember important themes from the beginning of a long piece when they reappear near the end. Thus a connectionist music listener should ideally include a means of determining and weighting what is to be remembered and what is better forgotten.
It should also be noted that these systems only use IOIs to evaluate rhythm. There are actually a great many more factors which determine our perception of rhythm and which are available for inclusion in a rhythm-detecting algorithm. Consider the example on the following page.
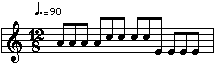
A rhythm detector that evaluates only on the basis of IOIs derives only a picture of constant eighth notes from this excerpt. The real interest of the rhythm, though, (and the real "point" of the excerpt) is that the dynamic accents and the pitch contour present two different additional rhythms: there is a dynamic accent every three eighth notes and a change of pitch every four eighth notes. This type of interplay of different rhythms occurs frequently in almost all Western music, and is often at least as important as the rhythm of the IOIs alone. (In fairness, it should be noted that Rowe's beat tracker is only one part of a more complex system and does in fact interact with other agents which detect dynamic accent and harmonic rhythm. His goal was to provide the improviser portion of Cypher with useful input information more than it was to design the perfect beat tracker.)
Finally, it is important to point out that neither of these connectionist systems particularly admits to syncopation as a valid rhythmic possibility. Syncopation is considered a contradiction of the beat (and indeed this is what any music theory textbook will assert). Still, there are cases in certain very common musical styles in our culture, notably jazz and rock, where certain syncopated rhythms are so characteristic as to be recognizable with no indication of the beat, thus evoking a sense of regular beat where virtually none is audible. By way of example, consider the following set of IOIs: 500 500 333 500 617 617 333. A jazz musician would be likely to notate it in cut time (or perhaps common time) as:

Whether we consider the half note or the quarter note as the beat, the rhythm is off the beat more frequently than it is on. However, a familiarity with this rhythm as being characteristic of a certain musical style leads some listeners to posit a beat which is evidenced only vaguely. Comparison of the IOIs in this example as simple ratios of each other could easily lead to discovery of the underlying eighth note pulse, but there is little evidence of an 8/8 grouping in the IOIs themselves. It would appear that the (relatively effective) connectionist systems discussed here could be supplemented by additional heuristics involving hierarchical structuring, knowledge base of stylistic signatures, and pattern comparison.
The objection usually made against including knowledge of style in an algorithm for music cognition is that style-dependent knowledge breaks down when applied to other styles of music. The implication of such objections is that an algorithm which does not employ knowledge of style is more general and objective. We often forget, however, that even our most fundamental ideas about music are usually dependent on culture.
With particular reference to cognition, it is clear that psychologists of music run a grave risk trying to interpret the results of localized, culturally based experiments in general terms....Consider the following claim:
"It seems intuitively clear that, given a sequence of notes of equal duration and pitch in which every note at some fixed [time] interval is accented, one will hear the accented notes as initiating metrical units that include the following unaccented notes."
Yet nothing could be less 'intuitively clear' to an ethnomusicologist: exceptions abound, most notably in various cultures of continental and insular Southeast Asia, where exactly the reverse perception would be normal.[10]
I was recently among a group of university graduate students and faculty of music who were all baffled by a flamenco dancer's way of counting out the accent patterns of the soleares and the bulerías. It seemed that her accents were all in the wrong places until we realized that in these dances the accent falls at the end of a grouping. Thus, the basic pulse of these flamenco forms is counted:
> > > > > 1 2 3 4 5 6 7 8 9 10 11 12
These comments are certainly not meant to deprecate any cognitive model of rhythm perception that cannot evaluate Bach, Boulez, Coltrane, and Sabicas with equal accuracy. It is simply to point out that what is often referred to as the correct evaluation of music is in most cases really a correct evaluation.
Why do we desire this evaluation of what we hear (which usually includes a reduction and modification of the sonic information)? What do we want to do with it once we have it? These questions inevitably influence what we measure in music, how we represent what we have measured, and how we process the data as represented. A quest for insight into our own mental processes is one rationale for this activity. But what does a listener do with musical information?
Anyone who is active in musicmaking--a performer, improviser, composer, sound technician, etc.--is constantly listening, deriving ideas from what she/he hears, and using those new ideas to influence new musical sound. An evaluation of rhythm, or any other similarly derived musical information, can be used as initial data (inspiration, if you will) in a generative process. This generative process may also be implemented as a computer program: as a compositional or improvisational algorithm.
Before beginning a discussion of computers and composition, I must acknowledge that I often find it a bit boring to read about either computers or techniques of composition. Both topics can potentially be boring because writers usually deal exclusively with technicalities of how something gets done, and never address the more interesting topics of what gets done and why. I would like to discuss the general matter of aesthetic decisionmaking using computers: not only how a computer makes a decision, but also what constitutes an "aesthetic decision", and why should a computer be used to make aesthetic decisions.
Papers given by composers in universities deal almost exclusively with compositional techniques and strategies, specifically methods of pitch selection: "How I went about choosing the pitches that I chose." These discussions of only the how appear to assume that a) the how is important while the what and the why are not, b) pitch (and especially pitch class) is the most important, or even the only important, aspect of music, and c) that one method of choosing pitches is intrinsically more interesting than another, irrespective of other considerations. More likely, though, composers and theorists discuss technique of pitch selection because that seems to them to be the most easily quantifiable and explicable thing to talk about. So I contend that they stick to that topic more out of laziness than out of belief in its value.
Talks given by composers deal less frequently with the broad whats of composition: "What did I set out to accomplish? What did I in fact accomplish? What did I fail to accomplish?" Even when those whats are discussed, it is extremely rare to hear any discussion of why: "Why did I think that was worth doing? Why did I succeed or fail at my goal?" or even more specifically "Why does this passage sound good to me? Why did I choose this rather than that?" Not only are the whys more elusive and inexplicable, they are probably also more intimately personal. By stating one's personal whys, one discusses one's own values and tastes and thus leaves oneself open to ridicule as being misguided or a philistine. It's much easier and safer to talk about method (the how), in terms that are concrete and apparently objective and indisputable. If one can make it sound impressively complex (ideally by stating it in mathematical terms), so much the safer.
Quelle cause pouvait nous amener à rejeter toute spéculation esthétique comme dangerereuse et vaine, et, par le fait, à nous restreindre (non moins dangereusement) au seul projet: la technique, le "faire"? Étions nous à ce point sûrs de notre direction "poétique"? N'éprouvions-nous aucun besoin d'y réfléchir, de la préciser?...Était-ce embarras à s'exprimer sur un terrain aussi fuyant, alors que la technique du langage nous semblait davantage appropriée à notre capacité de formuler? Était-ce le manque de "culture", ou simple réaction contre les divagations à la philosophie chancelante?[11]
[What could have led us to reject as dangerous and vain all aesthetic speculation, thus restricting ourselves (just as dangerously) solely to the matter of technique, of "making"? Were we so certain of our "poetic" direction? Didn't we recognize any need to reflect upon it and define it? Did we shy away from expressing ourselves on such an unstable terrain, while the technique of musical language seemed more appropriate to our ability to formulate? Was it a lack of "culture", or simply a reaction against the delusionary babblings of a failing philosophy?]
Things that are concrete and indisputable are of limited interest because once you get 'em then you've got 'em and there's nothing much more to say. They're a basis upon which to build other, more interesting ideas, but as soon as something becomes just a simple fact it becomes rather trivial. That is by no means to say that technical how talk is worthless. Talking about compositional methods is very valuable for beginning composition students; the more technique one has at one's disposal (in almost any field) the better. But I contend that for most other people--either composers who already have their own techniques or people who will never compose--such information is of curiosity value but of little or no practical use. Hearing about compositional techniques gives non-composers the impression that they have received important insight into musical experience, but I suspect that this impression is illusory and that the information is actually quite useless to them. It is much more interesting to me to hear what a composer does and why than to hear how, and I propose that the what and why are more interesting and useful to non-composers, as well.
That being said, the possibility should also be considered that why is ultimately reducible to a complex algorithm of hows. That is to say, we may consider the explanation of why something is the way it is (Why do I like chocolate ice cream better than strawberry?) to be equal to the explanation of how that state was achieved. (By what mental process do I arrive at the discernment that chocolate is preferable?) An anti-intellectual stance would be that it's impossible to explain the why of an aesthetic choice as an algorithm of hows, or that it's somehow better not to know the algorithm. A more open-minded but perhaps slightly mystical stance is that there's something more to why than simply a set of hows: that any algorithmic explanation of the process by which we make a decision will always be incomplete. I tend to subscribe to this latter view in theory, although I think the degree of incompleteness of an algorithm can be made, for practical purposes, minuscule. The idea that decisions can be explained algorithmically is, of course, at the very heart of the field of artificial intelligence, because computers only know how to do things. They carry out instructions with no inkling or concern as to why they are doing them. Therefore, the business of programmers of artificial intelligence is precisely to turn whys into hows.
This leads us to a discussion of problems of aesthetic decisionmaking one encounters when using a computer to compose music. There are several levels on which one might address this issue. I will discuss a few hows: How can a computer make aesthetic decisions? How can a computer aid humans to make aesthetic decisions? How does the experience of using a computer change the way that humans make aesthetic decisions? These lead us to some slightly more ambiguous questions: Why use a computer to compose music? Why teach a computer to make aesthetic decisions? Should our aesthetic criteria change when considering computer music? How does a composer's responsibility (and sense of responsibility) change when a computer is used?
First, I will try to distinguish an aesthetic decision from other decisions. I describe an aesthetic decision as one which is made a) with an aim toward an aesthetic end and b) using aesthetic criteria. When I aim toward an aesthetic end I make a decision because I think it will lead to an interesting or pleasing result. (I don't mean to imply any specialized definition of words such as "interesting" and "pleasing". They are deliberately left ambiguous; I use them to encompass an appeal to both the intellect and the senses; I feel both words can apply to both types of appeal.) Something can be pleasing or interesting to us in its form (that is, the abstractions we derive from its form) and in its immediate appeal to our senses (our unconscious response). The art that attracts me most is that which maintains optimal levels of intellectual and sensual appeal. An aesthetic decision, then, is a choice which is made in an attempt to achieve an interesting, pleasing result, using criteria based on that purpose rather than criteria with some other basis.
To better explicate this, and to tie it back to my earlier discussion of composers and what they talk about, let's take the example of a composer selecting a pitch to write on the page. Assuming that the composer has already decided to use only the 88 possibilities presented by the piano (or 89 if we include the "null" note, silence), some criteria for decisionmaking are obviously still necessary. A number of aesthetic criteria may be used by the composer in choosing a pitch: melodic contour, harmonic implications, etc. But the choice need not necessarily be based on aesthetic criteria. The composer may have a pre-established system (an algorithm, a list, etc.) or the choice may be made arbitrarily (by aleatoric means). In these instances the composer would simply be following established rules of decisionmaking--something, as I have already noted, that computers do better and faster than humans. Still, the existence of those rules implies some prior aesthetic decision (either of commission or omission). An algorithm is being used because the composer decided at some earlier time that that algorithm would lead to a desired aesthetic result. How did the composer arrive at that decision? That previous aesthetic decision was presumably made using one of those same three methods: by using aesthetic criteria, or by using some other set of rules (themselves based on earlier aesthetic decisions), or arbitrarily (using some unknown criteria or no criteria). So we see that rule-based decisionmaking can always be traced back to some prior choice, either aesthetic or arbitrary. That is why I'm always dissatisfied listening to composers discuss their methods of pitch selection. They talk about the rules they employ, rather than the criteria that were used to arrive at those rules.
When we try to trace aesthetic criteria themselves back to prior choices (By what criteria did we decide to use those criteria?) we eventually arrive at some profoundly banal dead end such as "I just like it" or "I don't know" or "It doesn't matter". Nevertheless, the road that leads us to that dead end can have many interesting sights along the way well worth exploring. Furthermore, I contend that the type of dead end we reach in this sort of genetic reconstruction of an aesthetic decision has its own aesthetic implications. If we eventually boil an aesthetic decision down to "I just like it," we imply the validity of an attribute called taste, which is another elusive word opening a new can of worms. If we decide that our decision is based on some primal aesthetic criteria which can never be understood intellectually, we acknowledge a dimension of decisionmaking which is often called intuition. If we decide that an aesthetic decision can eventually be reduced to a point where one choice is as good as another (the "It doesn't matter" ending), then we imply that randomness can be the source of aesthetic results.
So far we don't know of a way for a computer to exercise genuine taste or intuition (these matters are discussed later), but randomness (or a very good facsimile thereof) is no problem at all for a computer. Indeed, almost all computer programs that make aesthetic decisions employ randomness on some level. Total randomness--also known as "white noise"--is rarely of aesthetic interest to most of us. We tend to desire some manifestation of an ordering force which alters the predictably unpredictable nature of white noise. To produce anything other than white noise, a computer program for aesthetic decisionmaking must contain some non-arbitrary choices made by the programmer. Therefore, no decisionmaking program can be free of the taste and intuition of the programmer.
Computer music can be roughly divided into two kinds: music composed with a computer and music composed by a computer. We can really only say that music is composed by a computer program if that program actually makes choices. A computer can make arbitrary choices, choices based on some "knowledge base" of aesthetic values determined by the programmer, or choices based on "acquired knowledge" (as in a Markov system or a neural network). If a computer is programmed to follow a set of rules that contains no element of choice, however, it is simply performing calculation and is thus performing strictly technical tasks of composition.[12] It is true that such computation may be so complex as to create results unforeseen by the user, but this is evidence only that the user is a weaker calculating machine than the computer, not that the computer is behaving intelligently.
It is not my intention to recapitulate the history of the use of computers in music composition. I will just point out that some of the basic areas of exploration were already being laid out in the late fifties. Composers and engineers at Princeton University and Bell Laboratories were already beginning to synthesize music with a computer, Iannis Xenakis was using a computer to calculate distributions of massive numbers of notes by stochastic means, and Lejaren Hiller and Leonard Isaacson introduced music composed by a computer (using a knowledge base of textbook rules of harmony, voice leading, and style).
Composers tend to be a rather willful and control-oriented lot, however, and although many have been interested in devising very explicit algorithms for composition with computer, interest in music composed by computer has been somewhat less prevalent. This is no doubt mostly due to the firm commitment of most composers to the idea of composition as personal expression, rather than as the product of a machine. It may also be partly due to the relatively uninteresting music produced by Hiller and Isaacson's program (it sounded like music written by some nameless, characterless nineteenth-century German composer: like music written by a music theory textbook), which seemed to confirm the notion that good music (as evaluated in terms of its effectiveness as personal expression) was beyond the capability of a computer. Needless to say, if effectiveness of personal expression is the measure of quality in composition, people will always come out ahead of computers. Obviously, though, personally expressive music is only one possible type. There can certainly be impressive music, which inspires us with its abstract form more than with its emotive power. This type of music might be well served by computers, and might eventually be effectively composed by them.
The programmer David Zicarelli has written interesting programs for composition and improvisation by computer. His program M makes stochastic improvisations based on the MIDI input it receives from a performer as well as the decisions for probability weighting which are made by the program's user. The program chooses notes to play, based on the input material, but its choices are limited within specific ranges of possibilities determined by the user. The program is very versatile and well thought out, and is able to produce a wide variety of stochastic textures, although the stochastic processes it uses impose a very distinctive methodology upon the user. Zicarelli has offered the user a variety of specific ways to generate new materials from the input. I am not personally interested in adopting his methodology, nor do I particularly find the resulting music interesting, but it is nevertheless a considerable accomplishment--an environment in which a non-programmer can explore the generation of music by stochastic means.
Another of Zicarelli's programs, Jam Factory, uses Markov processes to generate new materials based upon the MIDI input. Markov processes are specific ways of creating sequences of events based on an analysis of the sequences found in a particular model. An example might be to make an analysis of all the chord changes in all the chorales of J.S. Bach, find the degree of frequency with which each sequence of chords occurs, then compose a progression of chords which (by probabilistic decisionmaking) contains those sequences in the same relative proportions of occurrence. Although this type of process may seem like a fruitful field of exploration, and certainly does have some relation to the way we appear to remember and learn about events, I think it is vastly insufficient as a means of emulating a series of aesthetic decisions. Simply put, it makes the classic confusion of subsequence and consequence: because b follows a, a must have caused b. Using a Markov chain as a means of making aesthetic decisions completely ignores the whys of the original decisions on which the chain is modeled. To say that (to refer to my crude example) Bach uses the deceptive cadence more frequently than the plagal cadence but much less frequently than the half cadence certainly tells me something about frequency of occurrence but tells me nothing about when, where, and why one cadence might occur instead of another. As a result, most music composed by the use of a Markov process contains recognizable elements of the model, but none of the sense of purpose or consequence contained in the human-composed model. An alumnus of the UCSD Music Department, Tom North, has used high order Markov chains (analyses of longer sequences of events) very effectively as a variation technique. By varying the extent to which his variations matched the model, he was able to achieve some interesting progressions.
Zicarelli's work is well considered and of high quality, but the problem with trying to write any sort of general-use compositional algorithm (i.e., a program that will be general enough to be useful to many composers) is that there are at least as many ways of composing music as there are composers, and most free-thinking composers will not be content to use an algorithm devised by someone else. This means that a composer with ideas of how to use a computer to compose must either learn to program or hire someone else to do the programming of specific algorithms. It's hard to be expert in both programming and music composition, so the collaboration of musicians and programmers seems one good way of doing computer music. It is not so unusual these days, though, for a composer to be a competent enough programmer to get useful work done, especially with the aid of medium-high level environments such as cmusic and csound in the signal processing domain or MAX and HMSL in the MIDI domain. These environments have been created to take care of low level computing tasks, leaving the user free to deal with higher level issues more directly related to musicmaking.
Most of the computer music work that has been done at UCSD does not use the computer to make decisions. Rather, the computer is used to perform types and quantities of calculation which would be unthinkable by any other means. The digital signal processing capabilities of F. Richard Moore's cmusic program for sound synthesis have been the cornerstone of most of the work done here. Composers such as Roger Reynolds and Joji Yuasa have been particularly intrigued by the ability to simulate spatial movement of sound using cmusic, and by the ability--using Mark Dolson's phase vocoder program pvoc--to perform temporal compression and expansion of sounds without changing their pitch.
The professor at UCSD who has done the most work with computer-aided composition is Roger Reynolds. A number of his pieces--both for instruments and for tape--have been composed using two algorithms which he has named SPLITZ and SPIRLZ. These algorithms are two different ways of fragmenting and reordering an existing musical excerpt. The fragmenting and reordering can be applied to the representation of the sound (the music in its traditionally notated form) or to the sound itself (with "splicing" of digital recordings).
This fragmenting and reordering process is more a transformative one than a generative one. It modifies existing music instead of composing new music "from scratch". Thus, the algorithm itself in no way addresses the criteria by which the input material (the music to be modified) was composed. The algorithm is a strict rule-based transformer--a filter, if you will--with no element of imprecision, randomness, or decisionmaking.
Reynolds has often compared his SPLITZ and SPIRLZ algorithms to a very traditional type of algorithm used in music, the canon. The process of canon is simply to combine a melody (the input) with one or more imitations of itself (possibly transposed, possibly slightly modified), each of which has been delayed by a certain time interval. The result is a contrapuntal output: the original melody in counterpoint with its delayed imitation(s). That is the explicit definition of the algorithm of the canon, and Reynolds maintains that his algorithms are similar in that they act upon the input in a predictable, well-defined way to produce a predictable output. However, implicit in the canon of tonal music is a whole set of explicit classical rules of harmony and voice-leading to which the output must conform. These rules for the output profoundly affect the nature of the possible inputs. In the absence of these rules--or some similar body of rules restricting the nature of the output, thus restricting the nature of the input--the canon becomes a wholly trivial exercise. There is no very great pleasure in hearing melodic imitation for its own sake; it is melodic imitation that results in elegant and harmonious (or at least consistent) counterpoint which is the essence of the canon. Reynolds's algorithms have no such rules restricting the output (at least none which are explicitly defined) and therefore no restrictions on the possible inputs. While the lack of restrictions on input may be conceptually desirable, making the algorithm equally applicable to an excerpt of cello music as to the sound of a waterfall, it also means that there is no standard basis for judging the quality of the output. The output must either be accepted simply because it is the output (which would be like accepting any canon, no matter how uninteresting or displeasing, simply because it is a canon) or it must be evaluated, critiqued, and edited by the composer, using his musical intuition and taste or some unstated set of applied rules as a judge. This is certainly not a criticism of musical intuition, taste, and editing as valuable tools for a composer, but it is a demonstration that the comparison to the canon is incomplete.
Since Reynolds's stated goal as a composer is to create new musical experiences, it may in fact be necessary that he not explicate the output rules, but it is unclear then by what criteria he evaluates the output. Just as one cannot plug any old words into a given grammatical construction and assume that the sentence will make sense (much less be particularly worth saying), one cannot put just any input into such an algorithm and expect that its output will make musical sense. Clearly in such a situation the composer's role as a critical editor is vital. Furthermore, after extended experience with the SPLITZ and SPIRLZ algorithms, it is likely that Reynolds has developed a very strong intuitive sense as to what input material might yield interesting output, even without having explicit requirements for the nature of that output.
Reynolds's approach is very different from that of UCSD artist Harold Cohen, who has developed a program that drives a robot that makes line drawings. His aim has been to develop a self-sufficient intelligent drawing program. Cohen's program includes an entire system of elementary rules and skills, so fully developed that it requires no artistic input. In effect, it makes its own aesthetic decisions: it chooses specific drawing actions from among the infinity of possible actions, based on the knowledge that has been programmed into it of what will constitute an aesthetically pleasing result. Cohen's computer program fulfills our criteria for aesthetic decisionmaking and can thus aptly be called an example of artificial intelligence.
Nevertheless, as with any artist, some of the drawings produced by Cohen's robot have been found by Cohen to be more interesting than others. He exercises responsibility both as the designer of the program and by his selection of its best output. Even though Cohen's program automatically implements his artistic ideas to his satisfaction, he ultimately filters its output through his intuition and taste. If he didn't do the filtering, others (and the law of supply and demand) would.
The question of a composer's responsibility to listeners is unavoidable, whether the composer is generating the music or simply editing what the computer generates. When a composer asks an audience to listen to his or her music, there is an implication that the composer will take the responsibility to produce the best music possible. Not all composers take that responsibility with equal gravity, however, and a lot of mediocre music is produced as a result of that fact. That is not to say that responsible composers don't produce mediocre music sometimes, but at least it's not because of insufficient effort to produce good music. Almost every moment of our lives is now filled with some kind of music, and music which is mediocre because of laziness or other forms of irresponsibility is a form of sonic pollution. While I certainly would never approve of legislating against it, I would advocate against it. That's all that one can do, in any case, because responsibility in any art is a purely personal thing. Only the artist in question knows whether the maximum possible effort has been made to produce the best art possible. One can suspect another person of being an irresponsible composer, but only that person knows for sure.
There's nothing about irresponsibly composed mediocre music that is unique to computer music, though. One has always been able to produce irresponsible mediocre music just as well with a piano or with a pencil and staff paper as one can with a computer, so the computer does not in itself increase the flow of mediocre music. The computer does, however, contribute substantially to the ease with which it can be produced, and perhaps even contributes to the tolerance of it once it exists. These days it's pretty easy to make sounds with a computer. That means that programmers, more or less irrespective of their musical expertise, can produce sounds and call them music. Thus, it's easy to turn a computer into a highly mediocre composer, spewing out compositions like some kind of lobotomized Ernst Krenek (may he rest in peace).
Even now in the 1990's there still exists an awe of computer technology, spurred on by a constant barrage of gee-whiz reports in the media, which makes computer-anything very impressive simply because it was done with a computer. It's time we grew out of that. Furthermore, the specialized skill of programming is foreign to most composers and critics, and is therefore intimidating to them. They feel unqualified to criticize computer music because they do not understand its method of production (its how). They don't know whether what they are hearing represents the best or the worst that is possible with a computer, and without that knowledge --and usually with a healthy dose of the aforementioned computer awe--they hesitate to evaluate the music as they would any other music. Learning about the how of computer music is valuable to critics and music teachers so that they can better evaluate the success of the means by which the work was realized (how well the method achieved the desired result), but this shouldn't obscure aesthetic evaluation of what the composer made and why. (Computer music may demand new aesthetic criteria, however. I'll get to that presently.)
Several factors make it easier for a composer inclined toward irresponsibility to be more irresponsible when using a computer. First, the considerable task of programming and the fascination with defining the compositional process algorithmically means that a programmer/composer usually spends 95% of the time writing programs for a given piece, and 5% of the time considering its composition. Second, the joy of having finally succeeded in writing a bug-free composing program tends to make the programmer/composer happy with any result. The simple fact of getting the computer to do something algorithmically often makes one lose objectivity regarding the value of doing that thing in the first place. Third, there is a tendency to rely too heavily on prior high level aesthetic choices (choices made early on in the design of the program)--a reluctance to re-evaluate the system of rules, even if it proves flawed. This leads to the "artifact of the program" excuse: "That's just the way the program works." Well, who wrote the program? Finally, there is the temptation to rely on computer awe, in hopes that the audience will somehow ignore the shortcomings of the music due to a fascination with how it was produced. This may explain the prevalence of lengthy and detailed program notes that allude to the complex compositional processes used, the number of hours spent in Studio X, the impressive technology summoned to perform the task, etc.
Admittedly, computer music composers are pioneering a field which is relatively new, and much of what we hear from them is highly experimental. So it is reasonable to treat their efforts with compassion and understanding of that fact. However, it's a disservice to the whole process for either composers or their listeners/critics/colleagues to submit to any of these temptations to excuse insufficient attention to quality of product.
This brings us back to the issues of intuition and taste. The word taste in particular exists specifically to signify an ineffable quality of judicious aesthetic discernment and elegance. Thus it is in the very nature of the word that it be used to describe that particular sense of judgment and behavior that cannot be further explained. It is perhaps for this reason that relatively little has been written on the definition of taste. In preparing his article Le Goût et la Fonction,[13] Pierre Boulez was obliged to refer back to the eighteenth century.
Que diable suis-je allé chercher cette notion de goût! C'est bien fran�ais, me dira-t-on...Il y a longtemps que l'on n'en parle plus; le romantisme a tué cette notion infiniement intellectuelle...Ce n'est pas étonnant qu'il nous faut ressortir l'Encyclopédie pour remettre en honneur une notion désuète et abolie.
[What the devil am I doing looking for this notion of taste? "Very French," one might say...No one has talked about it for a long time; romanticism has killed this infinitely intellectual notion....It's not surprising that we have to dig out [Rousseau's] Encyclopedia to restore the honor of a suppressed antique notion.]
Nevertheless, Boulez does grapple with the issue of taste.[14] He effectively summarizes some of the prevalent views on the meaning and value of this word, and provides his own additional views. He first attacks the simplistic discussion-ending dismissal implied by the old saw "À chacun son goût." ["To each his own."]
Comme chacun sait, le bon sens et le goût sont les choses du monde les mieux partagées; personne ne s'avouera qu'il estime avoir moins de bon sens que son voisin; il lui semblerait également de la dernière infamie de se proclamer ouvertement inférieur sur la question de goût....Demandez à quelqu'un, même dans les plus atroces circonstances, s'il juge avoir mauvais goût; ou l'indignation, ou le mépris, ou la commisération se peindront sur le visage de votre interlocuteur....Chaque individu en état de juger s'estime autorisé, fondé, à manifester son goût....
[As everyone knows, good sense and taste are the most evenly distributed of all attributes; nobody will admit to having less common sense than the next person; it would be taken as the ultimate insult to be proclaimed in any way inferior in matters of taste....Ask someone, especially in the most atrocious of circumstances, if he believes himself to have bad taste, and his face will express either indignation, contempt, or pity....Every individual believes himself justified--authorized--to exercise his "taste".]
Nor does he accept Rousseau's solution for resolving the personal nature of taste: "Je ne vois guère d'autres moyens de terminer la dispute que celui de compter les voix..." ["I can see no other means to end the dispute other than with a show of hands..."]
Cela n'est pas si étrange, et se reproduit pour chaque concert, à mains frappées. Qu'est-ce qu'un applaudissement, sinon le vote d'une communauté qui ratifie son propre goût? Tout amateur...se rend à la salle de concert o� l'on joue son auteur préféré pour célébrer le culte de lui-même. Il reconnaît son goût dans le goût de l'auteur, s'en félicite et, en même temps qu'il l'applaudit, s'applaudit!...
Serait-je irrémédiablement déterminé par le goût d'une époque? Ou vais-je contribuer moi-même à en forger les éléments? Serais-je victime du bon goût de mon époque, ou de son mauvais goût? Dois-je me rebeller et faire abstraction de ses critères, dont apparemment, je ne puis devenir maître?...Rousseau nous fait sentir bien durement [la tyrannie de cette forme de démocratie]: "Au reste, le génie crée, mais le goût choisit."...Ne vaudrait-il pas mieux dire conventions, franchement?...Certains créateurs partiront d'une étroite adhésion au présent et tourneront progressivement vers une projection démesurée dans le futur...pourquoi sont-ils les précurseurs, et non les curseurs...?
[This is not so strange, and occurs at every concert in the form of hand-clapping. What is applause, if not the vote of a community ratifying its own taste? Every music lover...attends the auditorium where the music of his favorite composer is being played to celebrate the cult of himself. He recognizes his own taste in that of the composer, congratulates himself, and in applauding the composer applauds himself!...
[Am I then destined to be determined by the taste of my time? Or will I contribute to forging its very elements? Will I be the victim of the good or bad taste of my time? Must I rebel and analyze its criteria which, apparently, I can never master?...Certain artists will part with a strict adherence to the present and will progressively turn toward a grand projection into the future...why are they the precursors of taste, and not the "cursors"...?]
Boulez firmly maintains that taste can transcend its epoch and its culture. Joji Yuasa refers to this capability of transcendence as "touching the collective unconsciousness."
Il faudrait affirmer que le goût est lié à la transcendance....Il n'y a pas de goût absolu; mais pour autant que le goût tende vers cet absolu, intemporel, il ne peut le faire qu'en trancendant la culture et les donnés historiques localisées. D'o� il résulte que le goût a une double nature... "immanence et transcendance y sont synchronisées et indivisibles"...Dans la mesure où elle aura satisfait à cette dialectique de l'immanence et de la transcendance, une �uvre pourra...devenir un prototype du goût.
[One must agree that taste is tied to transcendence....There is no such thing as absolute taste; but insofar as taste tends toward this timeless absolute, it can only do so by transcending the restrictions of a localized time and culture. From this it follows that taste has a double nature... "immanence and transcendence are synchronized and inseparable within it"...To the extent that a work satisfies this dialectic of immanence and transcendence, it becomes a prototype of taste.]
Boulez ultimately concludes that an entity exhibits taste by successfully serving its function within a structure. Thus an event in a piece of music must serve its function within the structure of the piece, and a piece must serve its function within the structure of its cultural and temporal context.
En musique, comme en poésie, l'élégance n'est pas a dédaigner; j'aime employer ce mot élégance comme les mathématiciens et les physiciens lorsqu'ils parlent si magnifiquement de l'élégance d'un raisonnement, d'une hypothèse, d'une démonstration... Cette élégance, que je sache, n'a rien de frivole; elle est la suprême manifestation de la difficulté vaincue, le la désinvolture à faire oublier cette difficulté même. Dans ce sens, c'est une preuve de bon goût que nous accepterons volontiers: l'élégance, alors, n'est autre qu'une forme aiguë de la précision.
Il y a une fonctionalité du matériau...de phénomènes mis en rapport entre eux dans une composition....Qu'on ne pense pas que cela soit limité a des événements musicaux instantanés; il peut aussi bien en être ainsi avec de grandes structures....La musique, en effet, par le matériau qu'elle utilise, se rencontre avec...notre culture,...notre vie sociale...Ce qui m'amène à dire que le goût a beaucoup à voir dans le discernement que nous apporterons à choisir les objects intégrable réellement à une structure.
[In music, as in poetry, elegance is not to be disdained; I like to use this word elegance as do mathematicians and physicists when they speak magnificently of elegance of reasoning, of a hypothesis, or of a proof. As far as I know, there is nothing frivolous; it is the supreme manifestation of difficulty mastered, the ease of concealing the very existence of difficulty. In this sense it is a proof of good taste that we gladly accept: elegance, then, is an intense form of precision....
[There is a functionality of material...of phenomena related to each other within a composition....One mustn't assume that this is limited to individual musical events: the same can hold true for large structures as well. By the material it uses, music engages in an encounter with...our culture,...with everyday life...This leads me to conclude that taste is closely linked to the powers of discernment that we bring to bear in choosing objects which can truly be integrated into a structure.]
The preceding discussion presents the view that taste might be approached by the successful definition and fulfillment of structure and function. This is certainly feasible within the local, closed system of the musical structure of a piece, but it is another thing entirely to define precisely the relationship between a piece and its environmental, cultural context. The intelligent, tasteful fulfillment of musical function in society still requires knowledge which is much more difficult to algorithmize. This aspect of taste is (or at least appears to be) largely unfathomable to us, and thus appears to require our intuition.
In effect, the point at which our concept of intuition begins is the point at which our algorithmization of decisionmaking leaves off--the point at which we decide to stop trying to translate whys into hows. The basic question then is: do we stop trying to algorithmize decisionmaking because we have reached the immutable barrier of the undefinable, or because we simply chose to cease further pursuit of the matter and to rely on our unconscious knowledge? I believe that in the theoretical sense the answer may ultimately be the former: some aspects of our intellectual behavior will probably never be fully known. In practice, however, the answer is that, for whatever reason, one simply stops systematizing and adopts intuitive methods.
Computer scientists interested in developing artificial intelligence are thus assured topics of study for a good long time; they will be able to continue to try to define intuition systematically. For a composer, the question of how deep one goes into the process of algorithmizing intelligence is probably determined by a) the extent of one's interest in unraveling the mysteries of intuition through artificial intelligence research, and b) the extent of one's faith in, and enjoyment of, the use of intuition in composition.
The pleasure (and pleasurable agony) that I personally derive from making aesthetic decisions myself by largely intuitive means is a major factor in determining how actively I pursue development of intelligent compositional algorithms. My interest in the use of algorithms is more to a) gain insight into my own hypotheses regarding the workings of my own intuitive processes by implementing them as computer programs (one might think of this as an analysis-by-synthesis approach), b) gain insight into aspects of arbitrariness in my compositional decisions by abdicating certain of those decisions to a computer program which ultimately has some arbitrary (random) component at the base of its decisionmaking process, and c) explore the applicability of some specific abstract idea (musical or extra-musical) to music composition.
My first efforts in programming compositional algorithms were the prt and etc programs, which I used to compose, respectively, Degueudoudeloupe for computer-generated tape and ETC for harp (or piano) and computer-generated tape. Both of those programs compose musical phrases which overlay different patterns of pitch contour, dynamic accent, and timbral accent--thus creating multiple simultaneous perceivable rhythms--and perform metric modulations based on the rhythms created. The programs require considerable input from a composer, regarding phrase lengths, periodicities implied by different patterns, etc., so they are far from being independent composers. Still, they do make aesthetic decisions based on a rudimentary set of aesthetic criteria. My interest in writing and using the programs was a) to test my intuitively formulated hypotheses regarding the relative strengths of different types of pattern in determining a listener's perception of where the beat is (cf. pp. 71-72), and b) as a means of exploring the extent to which I could remove myself from the process of intuitively choosing every single note and transplant myself to the level of making only general descriptive statements about a musical phrase, yet still be musically pleased by the composition. These are examples of interests a and b described in the preceding paragraph. To demonstrate how interests a, b, and c all interact, I will discuss another program and a resultant composition: not only from the standpoint of how the program works, but also what I set out to accomplish and why.
Entropy is the title both of a computer program for composing music and of a visual/musical composition for Macintosh computer and Yamaha Disklavier (computer-controlled piano) which I composed using that program. Entropy was largely inspired by the following passage from The Open Work by Umberto Eco:
Consider the chaotic effect (resulting from a sudden imposition of uniformity) of a strong wind on the innumerable grains of sand that compose a beach: amid this confusion, the action of a human foot on the surface of the beach constitutes a complex interaction of events that leads to the statistically very improbable configuration of a footprint. The organization of events that has produced this configuration, this form, is only temporary: the footprint will soon be swept away by the wind. In other words, a deviation from the general entropy curve (consisting of a decrease in entropy and the establishment of improbable order) will generally tend to be reabsorbed into the universal curve of increasing entropy. And yet, for a moment, the elemental chaos of this system has made room for the appearance of an order...[15]
This simple observation of the relationship between chaos and order, combined with other things I was reading at the time, set me to wondering if there were a way to explore the importance of probability and expectation in music in a new way and make a good piece of music in the process. Many people have advanced unsupported hypotheses regarding the role of probabilistic analysis of events in influencing our musical expectations; some even have gone so far as to state (again with no real evidence) that we rely solely on probability and expectation in our musical perception. My main objective was not to prove or disprove definitively any such particular theory of perception. My interest was simply to explore this region of inquiry, somewhat systematically and somewhat intuitively, to see what its importance really was (or could potentially be) in my musical thinking.
The approach that seemed most fruitful was to try to apply a simple implementation of information theory to composition with a simple program for making purely probabilistic low-level compositional decisions, to see if they provoked a "probabilistic way of listening" in me and in others. An information theory approach to music perception might hold that each musical sound is information which is stored in some way, and that this stored collection of past musical events is used to form probabilistic expectations of what will happen in the future. My questions were: To what extent does such a process operate in my music perception? How easily does this theory break down? Could the ideas be extended to embrace the complexity which seems to cause the theory to break down? Can a simple version of the ideas be useful if the complexities are dealt with intuitively by a human?
Information is defined by Gregory Bateson as "Any difference that makes a difference."[16]
It takes at least two somethings to create a difference. To produce news of difference, i.e., information, there must be two entities (real or imagined) such that the difference between them can be immanent in their mutual relationship; and the whole affair must be such that news of their difference can be represented as a difference inside some information processing entity, such as a brain or, perhaps, a computer.
There is a profound and unanswerable question about the nature of those "at least two" things that between them generate the difference which becomes information by making a difference. Clearly each alone is--for the mind and perception--a non-entity, a non-being. Not different from being, and not different from non-being. An unknowable, a Ding an sich, a sound of one hand clapping.[17]
My own definition is that "Information is one or more bits of awareness." These bits are combined in some way by an information processor (anything which Bateson would classify as a mind--a brain and a computer are two examples he gives) to produce (or fail to produce) knowledge and meaning.
One apparent difference between Bateson's definition and my own is his insistence that "It takes at least two somethings to make a difference." I argue that the "difference", which I agree is essential, occurs at the processing stage--a difference is noted between a bit of awareness (a "something") and the current state of the information processor. That is, the current state of awareness of the processor is one "something" with which a second "something" is combined.
In most instances this is not a profound difference of opinion; rather, it is simply the result of two ways of stating the same situation. In fact there is no such thing as a Ding an sich, existing in a void. A thing, as Bateson himself points out, "is precisely not the 'thing in itself'. Rather, it is what mind makes of it, namely an example of something or other." Everything is perceived as different from its absence, and each moment in time is different from the previous one.
A second distinction between definitions is in the second clause of Bateson's statement--his requirement that a difference must "make a difference", that it must be a perceptible and significant difference. I see this, too, as being a function of the information processor. We may receive information but regard it as insignificant (e.g., things seen out of the corner of our eye, the noise floor in a room full of people). The information simply does not produce a difference sufficiently great to substantially alter the functioning of our information processor. That a bit of information does not alter the functioning (or "output") of the information processor does not mean that the information never existed. It may have altered the state of the processor in a subtle way which, in combination with other future bits of information, will "make a difference". Similarly, information may simply be redundant, duplicating information which as already been received, and not altering the state of the processor in any way. I therefore include insignificant and redundant information in my definition, whereas Bateson excludes them because they don't "make a difference."
So what is musical information, and how does it make a difference to us? I approached the question in intentionally naïve and unscientific terms: I posited a situation in which I (with my "information processor") am situated in a concert hall; on-stage I see a person seated at a piano; I close my eyes; the room is, for all practical purposes, silent; I hear a single piano note.
What bits of awareness have I received? In standard parametric musical terminology, I heard a note having a certain pitch, amplitude, timbre, and duration. What might a proponent of information theory say takes place in my information processor? My processor already contained a lot of information (knowledge that I'm in a concert hall, knowledge of what usually occurs in a concert hall, knowledge that I'm likely to hear piano sounds, knowledge that I have not yet heard any sounds, etc.), so these three new bits of awareness can potentially make a difference. I now know that the piece is underway because the note is different than the preceding silence. I am not surprised that the note has the timbre of a piano because the piano is the only sound-producing object I have seen (excluding the human, for purposes of simplicity). Thus the timbre information is insignificant to me. I know that the note was of a certain loudness, which (if I call upon my knowledge of a piano's loudness capabilities and my distance from it) I can even characterize with a specific term such as mezzo piano. I know that the note was short (relative to what I know to be the speed limitations of a human player and the sustaining capabilities of a piano), and I can characterize it with a term such as staccato. If I had perfect pitch (I don't) I would know that the pitch was F below middle C; as it is, I know that it's a pitch slightly below middle C and that I'll recognize it (and its pitch class) as being the same if I hear it again.
Already my information processor appears to have used expectation and comparison in all sorts of ways. Based on past experience I had a very high ratio of confidence (i.e., probability was high) that the first piano sound I heard was significant as the beginning of a piece of music and was not just the pianist warming up. I instantly classified the timbre as insignificant because my processor contained a very high probability that I might at any moment hear piano timbre and the new information did nothing to alter that probability. Likewise, past experience has provided me with a range of expectations for the pitch, loudness, and duration of piano notes, and ways of situating new information within those ranges.
How does this information change my expectations? I now expect to hear additional notes, based on my knowledge that there is an extremely high probability that the piece is more than one note long. I still expect the ensuing notes to have the timbre of a piano, but I have virtually no basis for any expectation regarding its pitch, loudness, or duration: probabilities are all more or less equally low because a piece can continue in such a large number of ways. A little more than a second later, I hear a second note.
In addition to the information of pitch, amplitude, timbre, and duration, the difference in time between the onset of the two notes has provided me with another bit of awareness: the inter-onset interval. Information in the other parameters has provided evidence of repetition--of sameness. It is significant to note that repetition in music is not the same as redundancy in information theory. No event or information can be redundant in music simply because it is a repetition, since repetition reinforces probability and expectation. In music, an event happening twice does not have the same meaning as an event happening once. Repetition may be so common, however, that the significance of new information can be greatly reduced: an event happening 98 times in a row is not so very different in its musical significance from an event happening 99 times in a row.
What effect does this information of repetition have on my idea of probability and expectation? Do I now expect a third note with the same IOI and parameters? After all, the evidence tells me there is a 100% probability that the third event will be a staccato, mezzo piano, F piano note occurring 360 milliseconds after the second event, right? Well, no, for two reasons. The first reason is because we have not accounted for the probabilistic influence of all my prior experience of music, which tells me that in a great many cases parameters are varied in music. Information from my more long term, global past is in conflict with my more local, short term past. The second reason is because of Ockham's razor.
We often hear people quote the general principle, known as Ockham's law, that one should always make the simplest conclusion possible based on available evidence. Thus one should make the simplest prediction of the future based on evidence from the past. Unfortunately, in this case we don't really have all the evidence. We only know what has happened, but we have no knowledge of how or why it has happened; no knowledge of what rules govern its behavior; in short, absolutely no reason whatsoever, even after 99 repetitions, to believe that it will happen a 100th time unless we have some other knowledge of why it will or will not occur. Even if I should, by some chance, flip a coin (that I know to be unbiased) 99 times and get heads 99 times, I know that the odds are still even on the 100th flip. Past evidence is only evidence, not a reason for the evidence. That is the important implication of Ockham's razor--the fact that past events do not determine the future--for musical applications of information theory. In music, expectation for the future is not solely dependent on probabilistic analysis of past evidence because as listeners we know that a composer has free will and can do something new (or not) at any time.
That having been said, however, it is also true that we do not ignore the evidence when listening to music, especially evidence from our local, immediate past. Regardless of what I may know to be possible, after 99 repetitions of the same thing I will very likely expect a 100th occurrence. That is because the repetition has impressed a pattern upon me, and that pattern has become a theme or motif which I recognize to have some aesthetic significance in the context of the piece. Even a single repetition can have this effect, thus I might have some increased expectation that the repetition indicates regularity. However, the hypothetical piece continues:
Clearly, after only three notes of an extremely simple piece of music (which may eventually prove to contain thousands or millions of notes), the complexity of what our hypothetical information processor has to store, manage, and derive musical significance from has grown substantially. Not only does our information regarding parameters and IOIs increase (more or less linearly with each new note), but we begin to see an exponential proliferation of contrasts, similarities, and resultant patterns when that information is analyzed. Again, probabilistic analysis shows itself to be insufficient to explain our expectations. To take just the parameter of pitch, we might say that there is a 67% probability that the next note will be F, and a 33% probability that it will be G. In real life, though, we know that that is pretty useless information. Pattern analysis (Gestalt principles) might suggest F (closure), G (similarity), A-flat (closeness, good continuation), A (closeness, good continuation), or any of a number of other possibilities. Past musical experience tells us that our sample is too small to predict the next event, and Ockham's razor reminds us that indeed the next event could be anything--two or more simultaneous pitches, nothing at all, or even the pianist breaking into song. (Now that would be information!)
From this (admittedly banal and simplistic) mental experiment, I concluded that information theory is grossly insufficient as a basis for a theory of our (or at least my) perception of music of any complexity whatsoever. But that does not mean that probability and expectation play no role in musical perception, especially in cases involving considerable repetition, as noted on the previous page. To explore that role in an environment of controlled, variable complexity, I wrote a program which composes musical phrases that have specific probabilistic implications.
The Entropy composing algorithm is extremely simple, so I will explain its operation: the program composes a list of notes, concerning itself with only three attributes of each note: the loudness, the pitch class, and the octave in which the note occurs. First, the user of the program specifies a set of probabilities of occurrence for each possible loudness, pitch class, and octave at the beginning of the list to be composed, and another set for the end of the list. In addition the user tells the program how many notes to compose (the program does not concern itself explicitly with IOIs) and what exponentiality of acceleration to use for the progression of each attribute from its starting state to its ending state.
For each note the program composes, it asks itself where it is in its progress from the beginning to the end of the list, and calculates a set of instantaneous probabilities (somewhere between the starting state and the ending state) based on the accelerations that have been specified for its progress in each of the three attributes. Once the instantaneous probabilities have been computed, the program chooses a note stochastically based on those probabilities, advances to the next point in the list, and repeats the process until the end of the list has been reached.
The output is an ordered list of pitches and loudnesses which exemplifies the specified progression from the starting attributes to the ending attributes. The list is rhythmicized in any way (algorithmically or intuitively) and is then translated into a format for synthesis and/or notation (e.g., MIDI).
For a first piece using this program, I decided to use an ostensibly monotimbric instrument (the Yamaha Disklavier), to use simple motoric rhythms (i.e., a simple algorithmic reading through the lists at a constant velocity or according to some continuous curve of acceleration), and to use a very fast tempo in order to present a high density of information, thus making the progressions in the stochastic weightings evident over relatively short periods of time. These simple implementation decisions were made in order that the music create a very obvious presentation of the compositional process involved. However, the program's output list can be used equally effectively to generate melodies of arbitrary rhythm or granular textures for synthesis or orchestration.
My own goal with this program was not to devise an intelligent composer, but to create an exploration environment. Many decisions in the composition of the piece Entropy regarding how the outputs of many passes of the program should be combined (overlapped, spliced together, etc.) were made intuitively. Many of these decisions could clearly be algorithmized in future pieces.
How might one go about algorithmizing the input for this program? Considering only the attribute of pitch class, for a moment, one possibility is to use a pseudo-Schenkerian macro-structure for the harmonic progression of the piece, such as that used for the piece Entropy (shown below) which guided the choice of pitch class input into the program.
Each area of this basic macro-structure was "ornamented" by forays into more randomized territories, yielding a new type of harmonic prolongation which was very appropriate to the idea of the piece (exploration of negentropy versus entropy). A more detailed hierarchical version of such a macro-structure could easily be used as the basis for input rules of a different piece. For a more generalized implementation of such a harmonic structure, applicable to a variety of pieces, one would have to use an algorithmic system for generating harmonic macro-structures.[18] The type of transitions generated by the Entropy program are direct transmogrifications in which one state emerges from another. The harmonic system of the earlier etc program is considerably more complex, and moves from one state to another along a harmonically logical progression such as a circle of downward fifths or some other "flavor" of chord progression. This type of harmonic logic is achieved by progressing along a specific path of pitch classes, rather than simply shifting chromatically or (as in Entropy) shifting probabilities of occurrence.
A composing program can also get its necessary input information from its environment, by "listening" to a musical performance. Robert Rowe's Cypher program, discussed earlier, is an example of how a compositional algorithm can use input information derived from a musical performance to shape its compositional decisions. This realtime listening-evaluating-composing process is a simulation of human improvisation. Rowe's program takes an important additional step: it listens to itself. It feeds its own output back into its input to influence its future composition. This is a very reasonable thing for any artificial improviser to do (just as any human improviser does), since its own output immediately becomes part of the sonic environment. An algorithm's reflexivity and self-evaluation help it arrive at a musically coherent output. This points out the potential intimate connection between input recognition and output generation: when these are two parts of the same program and share aspects of structure representation, the compositional algorithm can function more intelligently as a result of its listening ability.
Once rules for decisionmaking at the low level (e.g., note choices) have been successfully defined, the process of uncovering further secrets of intuition appears to be one of algorithmizing the compositional process at an ever higher level of musical structure. In a more general sense, the barrier of understanding intuition is pushed back as one algorithmizes intelligent decisionmaking at an ever "deeper" intellectual level.
Computer scientists tend to concentrate on a specific model of intelligence: reference to knowledge bases and stylistic behavioral scripts, probabilistic decisionmaking based on information theory or Markov processes, pattern matching using Gestalt principles, knowledge acquired by activation of neural networks, etc. Such concentration may be necessary for the advancement of that specific computational technique. Most musicians know intuitively, however, and I believe I have demonstrated in this chapter, that intelligent musical behavior--whether in cognition, performance, or composition--indubitably involves use of more than one process simultaneously or sequentially. It is to be hoped that musicians and computer scientists can work together to combine the strengths of these different models of the musical mind.