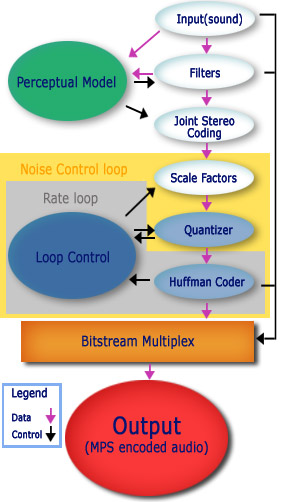
Perceptual Model
This part of the encoder (sometimes referred to as a Psychoacoustical Model or the Masking Model) analyzes the incoming signal and outputs values based on well-known pyschoacoustical phenomena. This is a critical stage and has a large play in the overall quality of the encoder.
It has two parts. First it processes the signal with a 1024 point FFT
. Second, the resulting information (phase and amplitude) is analyzed.
From this analysis, the Perceptual Model then accomplishes its two main functions. First, it tells the MDCT